Node.Js Certification (JSNAD)
Quote from Linux Foundation:
JSNAD certification demonstrates the ability to perform tasks in real world-type environments, giving employers confidence that the certificant possesses a broad range of skills around JavaScript and related technologies. Passing a performance-based exam demonstrates the candidate's ability to perform challenging real world tasks under time constraints.
The two-hour exam tests your skills from debugging Node.js to managing asynchronous operations to controlling processes. It tests knowledge and skills that an experienced Node.js application developer would be expected to possess. The exam is performance-based and includes items simulating on-the-job scenarios.
What to expect - https://www.nearform.com/blog/node-js-developer-certification-what-to-expect/
Books:
Content
-
Buffer and Streams - 11%
- Node.js Buffer API’s
- Incremental Processing
- Transforming Data
- Connecting Streams
-
Control flow - 12 %
- Managing asynchronous operations
- Control flow abstractions
-
Child Processes - 8%
- Spawning or Executing child processes
- Child process configuration
-
Diagnostics - 6%
- Debugging Node.js
- Basic performance analysis
-
Error Handling - 8%
- Common patterns
- Handling errors in various scenarios
-
Node.js CLI - 4%
- Node executable command line flags
-
Events - 11%
- The event system
- Building event emitters
- Consuming event emitters
-
File System - 8%
- Input/output
- Watching
-
JavaScript Prerequisites - 7%
- Language fundamentals
- Scoped to core language features introduced since EcmaScript 1 and still heavily used today
-
Module system - 7%
- CommonJS Module System only
-
Process/Operating System - 6%
- Controlling the process
- Getting system data
-
Package.json - 6%
- Package configuration
- Dependency management
-
Unit Testing - 6%
- Using assertions
- Testing synchronous code
- Testing asynchronous code
Important Content - yjhjstz/deep-into-node: In-depth understanding of Node.js: Core Ideas and Source Code Analysis (github.com)
Architecture Overview
Node.js is manily divided into four parts:
- Node Standad Library - Top level modules that we as developers use. Examples of this are http, Buffer, fs and so on.
- Node Bindings - It is a bridge between JS and C++. It encapsulate the details of libuv and V8, so developers don't need to worry about those details.
- V8 (C/C++) - Is a javascript engine developed by google and it is the same one that is used on Chrome.
- Libuv (C/C++) - Is a library that provides cross-platform asynchronous I/O capabilities.

Libuv
Node.js uses V8 as the javascript runtime, and to support asynchronous event-driven I/O libev was chosen. Libev only supports unix, so after gaining some popularity they switched it to libuv that supports Windows, freeBSD and OSX, by using the event notification accepted by each one of those OSs.
Libuv architecure

For network I/O-related requests, depending on the OS platform libuv will use:
- epoll on Linux
- kqueue on OSX and BSD-like OS
- event ports on SunOS
- IOCP mechanisms on Windows
For requests represented by File I/O, DNS ops and user code, thread pool is used. The asynchronous request processing is implemented using the thread pool method, which can be well supported on various OSs.
V8
V8's execution process follows roughly these steps:
flowchart TD
SC[Source Code] --> Parser
Parser -- Transform tokens into --> AST[Abstract Syntax Tree]
AST --> Ignition[Ignition Interpreter]
Ignition -- Transpile into bytecode --> BC[bytecode]
Ignition -- When it is a hot path with predictable shape --> Turbofan[TurboFan Compiler]
Turbofan -- Transforms into optimized --> MC[Machine Code]
MC -- If the shape changes too much it deoptimizes code --> BCV8 more directly converts the abstract syntax tree into native code through JIT technology, abandoning some performance optimizations that can be performed in the bytecode stage, but ensuring execution speed. After V8 generates machine code, it also collects some information through Profiler to optimize native code. Although there are fewer performance optimizations in the bytecode generation stage, it greatly reduces the conversion time.
V8 Architecture Overview
V8 has 4 major parts:
- Isolate - Is an independent virtual machine corresponding to one or more threads.
- Context - Is a javascript runtime, that allows you to keep your global things.
- Handle - Is a reference to an object that v8 will manage (creation/destruction)
- Scope - Is a collection of handles that allows V8 to manage handles more easily by thinking on groups.
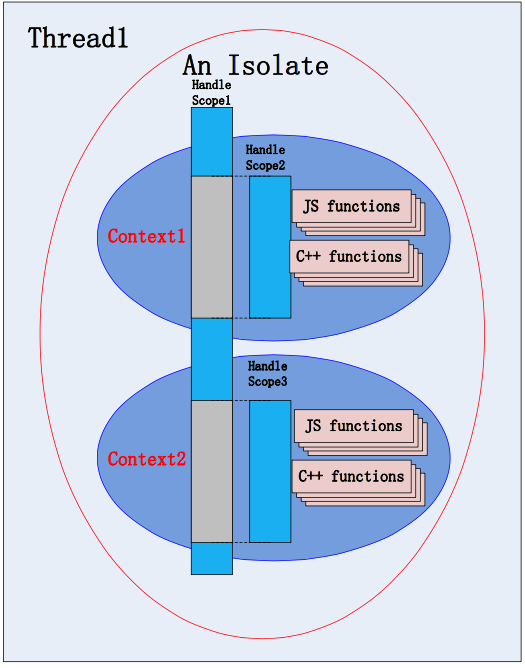
Isolate
An isolate is an independent virtual machine that has one or more threads, but can only enter in one thread at a time. They are completely isolated so they can't share resources with each other. There is always a default isolate, but more can be created explicitly.
Context
A context can be considered a runtime environment. Contexts allows javascript scripts to have global things like environment variables and global functions, also when creating bridges between javascript and C++ those functions/modules will be added to the context.
Contexts can be nested, which means that one context can create another. One example of this is when there are iframes in a page. The main context will be the page itself and the nested contexts will be the iframes.

Scope
Scope is a group of handlers. They allow v8 to instead of managing handles one by one, manage the group. There are 2 important scopes:
- Context::Scope - Groups handles for a context
- HandleScope - Manages local handles
Let's say the you call a function. In the beginning of the function a scope will be created and all objects created in this call will be added to this scope. Once the function is finished, v8 will release all handles associated to this scope.
// Handles in this function will be managed by handleScope
HandleScope handleScope;
// Create a js execution environment Context
Handle<Context> context = Context::New();
Context::Scope contextScope(context);
// Other code
Handle
In V8 memory allocation is performed by V8 Heap, and JS values and objects are stored on it. This Heap is maintained by V8 and objects that lose their references will be GCed. A handle is a reference to objects on V8 Heap and GC uses this reference to know if objects can be collected , when the Handle reference of an object changes, GC can recycle or move the object.
There are 2 types of handles:
- Local - Handles that are managed by handle scope
- Persistent - Handles that are managed by context scope

Garbage Collector
Orinoco: The new V8 Garbage Collector Peter Marshall - YouTube
Garbage Collector in V8 Engine. The process of GC involves identifying… | by Moshe Binieli | Medium
Garbage collection is the process of tracking live object and destroy unreferenced object in the heap memory to make room for new object thus saving memory. V8 has its own garbage collector that is responsible to manage the lifecycle of javascript objects.
V8's Garbage Collector has these main tasks:
- Identify live objects
- Recycle/reuse the memory occupied by unreferenced objects (dead objects)
- Compact/defragment memory
V8 Heap is divided in two groups, young generation with nursery and intermediate and older generation. When objects are created they are put on nursery and they move to other stages if they survive GC collection.
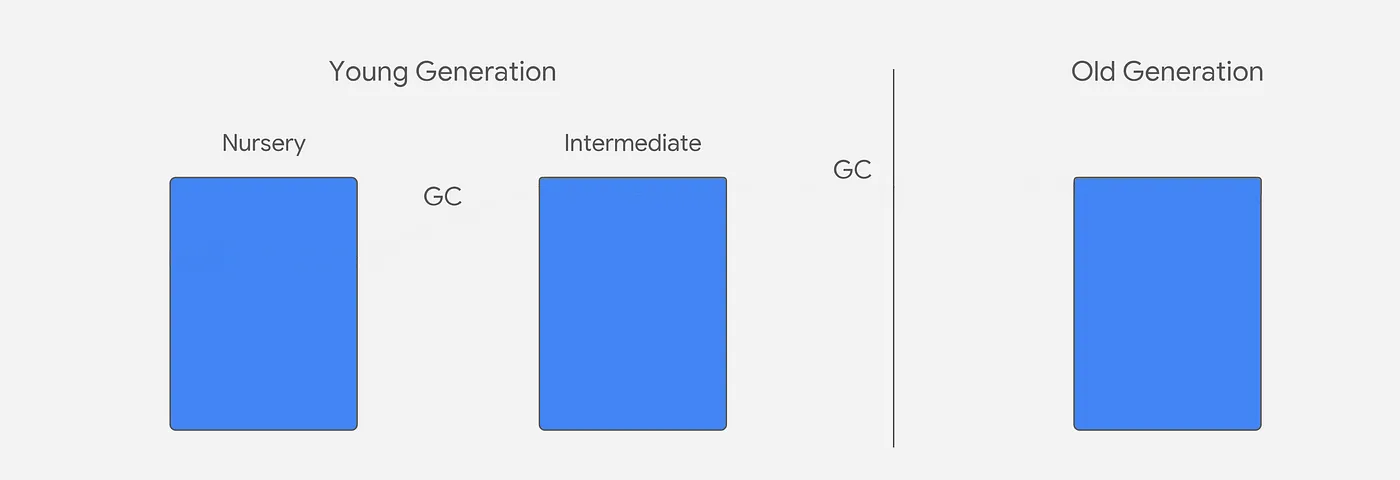
The garbage collector runs under the assumption that most of the objects will die young, so the focus is put on young generation. Because of that there are 2 GCs that work independently:
- Scavenger (minor GC) - Focus on young generation
- Full Mark Compact (major GC) - Focus on old generation
Before we start explaining how they work, here is some important terminology:
- Pages - Are memory chunks of 512kb
- Root - is the starting point for GC collection, it includes the execution stack and global object.
Scavenger (minor GC)
There are 3 steps on scavenger:
- Marking - Scavenger checks on nursery which objects are live by verifying if they are reachable from the root level. The ones that are receive a mark.
- Moving - Objects are moved from nursery to intermediate, the ones that already had a mark are moved to the old generation. Once everything is moved, nursery and intermediate are swapped.
- Updating - The old references are updated to the new ones.
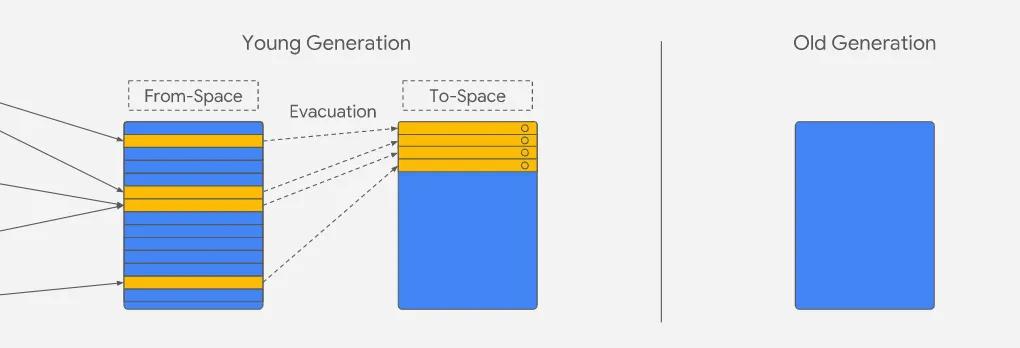
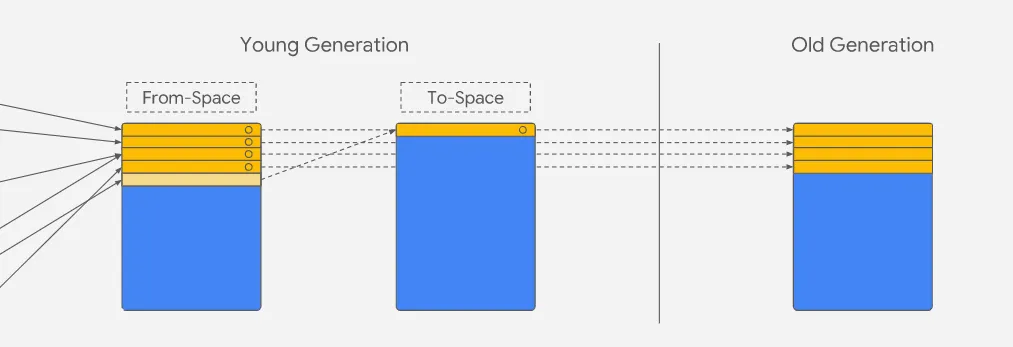
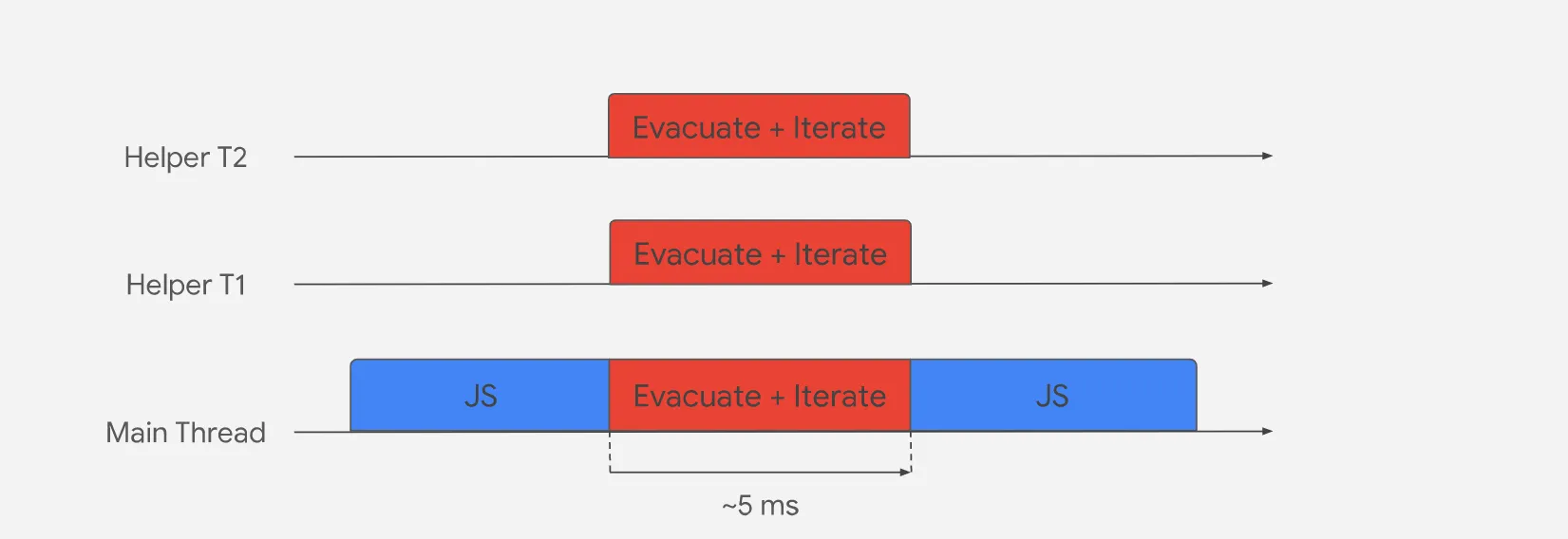
V8 uses parallel scavenging to distribute work across multiple helper threads, where each thread will be assigned a certain number of pointers to follow and will evacuate any live object to intermediate/old generation. The tasks must coordinate when attempting to evacuate an object.
Full Mark Compact (Major GC)
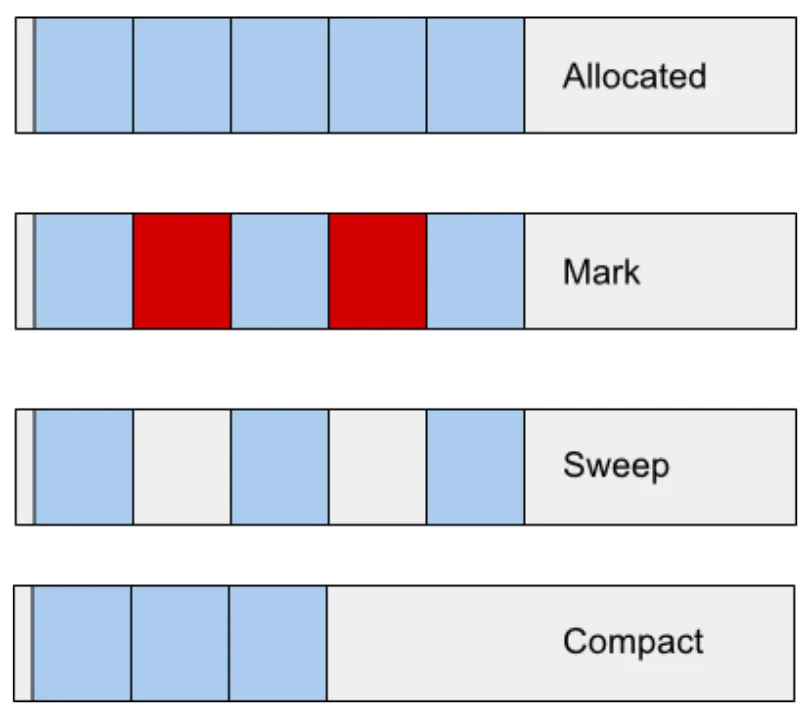
Full Mark Compact has responsibility over the whole heap, but runs less frequently. It has the following responsibilities:
- Marking - Identify reachable objects from the root (alive) and marks them.
- Sweeping - Compacting can be a costly operation, so instead of always compacting, most of the time it will add the free spaces left from dead objects to a "Free List" for quick access. When allocating memory we can check the free list and choose one with the appropriate space.
- Compaction - The garbage collector uses an fragmentation heuristic to decide which pages to compact.
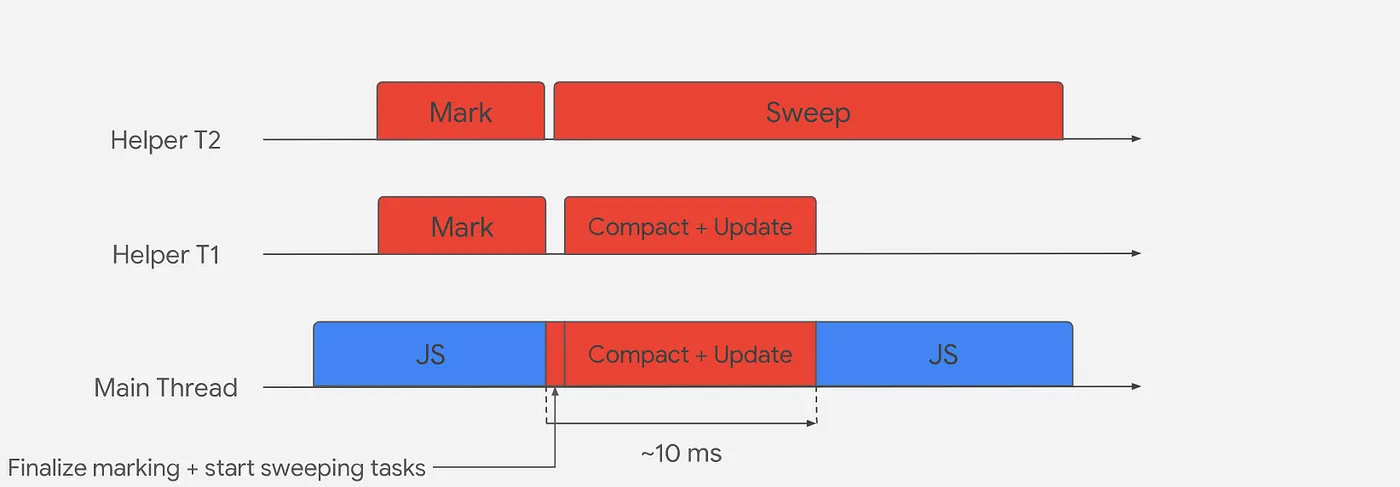
Full Mark Compact GC runs concurrently since it deals with more data. Once this GC Cycle is approaching it spawns helper threads to start marking objects while javascript is still running in the main thread.
Once the concurrent marking is over or the dynamic allocation limit is reached the main thread pauses and finishes the rest of the marking phase ensuring that no object was left behind because of new code execution between the concurrent marking phase. Once this is finished 2 things happen in parallel, compacting and sweeping.
The compacting phase will happen in multiple threads concurrently for the pages that the GC considers necessary, once this step is finished the main thread can continue.
While this is happening sweeping process is also happening concurrently, marking the deleted areas as "free spaces", this can continue happening even after the main thread continues to run
GC/Memory Questions
- What happens if an object is bigger than a page (512kb)? - When an object is larger than a single page it will spawn through multiple pages, causing slower memory access, reducing memory deallocation , making GC take more time.
C++ and JS integration
Since there are big differences between C++ and JS data types, V8 provides the Value class which is used from Javascript to C++ and from C++ to Javascript. (Integer is a subclass of Value.)
Handle<Value> Add(const Arguments& args){
int a = args[0]->Uint32Value();
int b = args[1]->Uint32Value();
return Integer::New(a+b);
}
In V8, there are two template classes:
- ObjectTemplate - C++ objects can be exposed to the script environment.
- FunctionTemplate - is used to expose C++ functions to the script environment for use by scripts
Sharing variables between JavaScript and V8 is actually very easy. The basic template is as follows:
static char sname[512] = {0};
static Handle<Value> NameGetter(Local<String> name, const AccessorInfo& info) {
return String::New((char*)&sname,strlen((char*)&sname));
}
static void NameSetter(Local<String> name, Local<Value> value, const AccessorInfo& info) {
Local<String> str = value->ToString();
str->WriteAscii((char*)&sname);
}
After defining NameGetter and NameSetter, register them on global in the main function:
// Create a template for the global object.
Handle<ObjectTemplate> global = ObjectTemplate::New();
//public the name variable to script
global->SetAccessorNew("name"), NameGetter, NameSetter;
Calling C++ functions in JavaScript is the most common way to script. By using C++ functions, the ability of JavaScript scripts can be greatly enhanced, such as file reading and writing, network/database access, graphics/image processing, etc.
In C++ code, define a function prototype as follows:
Handle<Value> func(const Arguments& args){//return something}
Then, expose it to the script:
global->SetNew(func);
Event Loop
Javascript is single threaded, the main javascript code runs on the Call Stack. The stack keeps track of the functions that are being executed and it runs them synchronously using FIFO.
To perform non-blocking I/O operations Node.js uses the event loop, which offload operations to the system kernel when possible.
Operating system kernels are often multi-threaded, so they can handle multiple operations at the same time running in background. When these operations completes the kernel tells Node.js to add the callback associated to this operation to be added to the pool queue.
The event loop keeps checking if the call stack is empty, and if it is, it adds the callbacks to the call stack to be executed.

Event loop phases overview
When Node.js starts, it initializes the event loop, runs the script and if this script triggers async calls, schedule times or call process.nextTick() they will be sent to event loop.
The event loop has multiple phases and each phase has a FIFO queue of callbacks to execute. When the event loop enters in a specific phase it will perform the operations specific to that phase, then execute callbacks in that phase until the queue has been exhausted or the maximum number of callbacks is reached, then the event loop will move to the next phase.
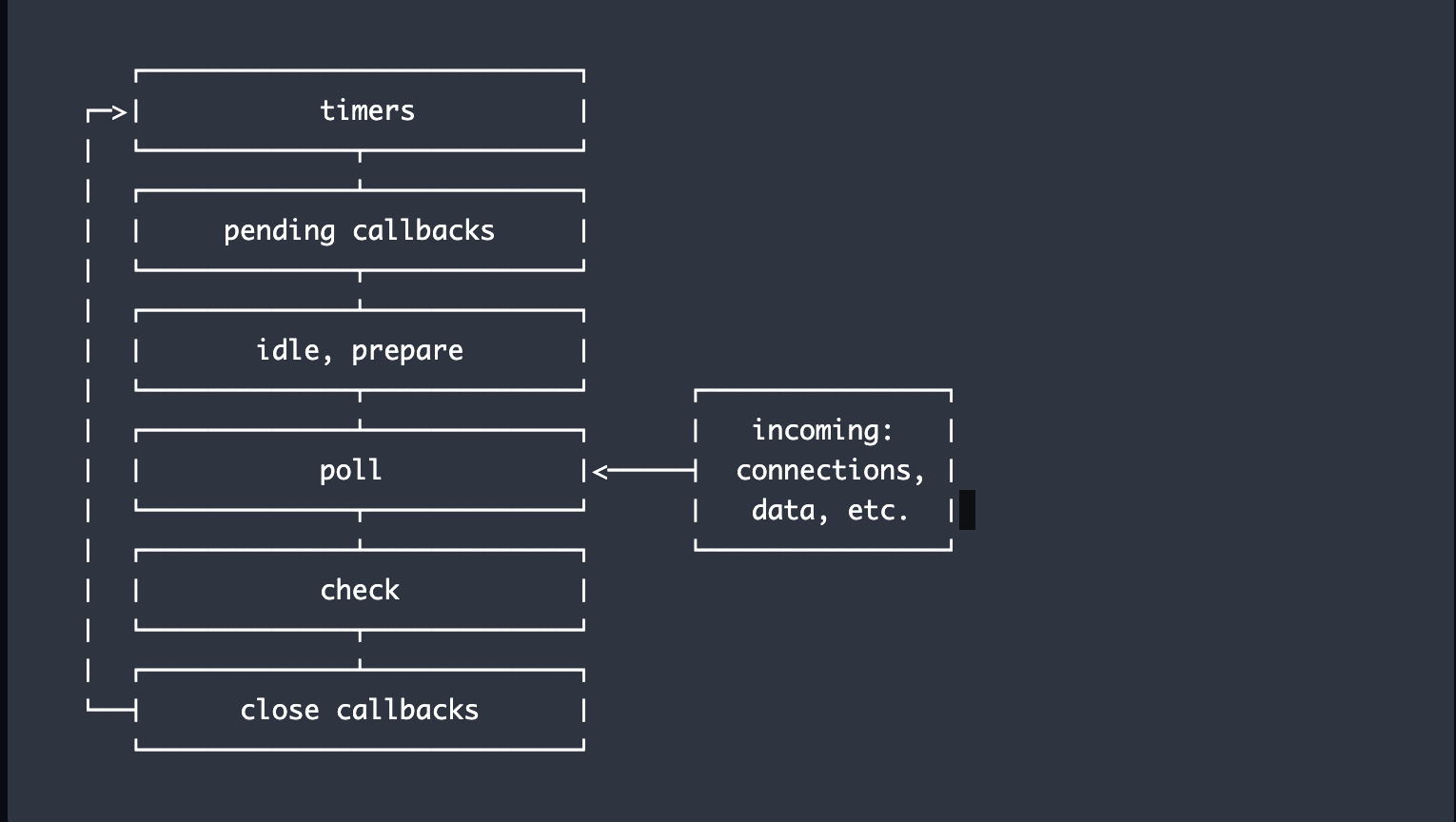
- timers: this phase executes callbacks scheduled by
setTimeout()andsetInterval(). - pending callbacks: executes I/O callbacks deferred to the next loop iteration.
- idle, prepare: only used internally.
- poll: retrieve new I/O events; execute I/O related callbacks (almost all with the exception of close callbacks, the ones scheduled by timers, and
setImmediate()); node will block here when appropriate. - check:
setImmediate()callbacks are invoked here. - close callbacks: some close callbacks, e.g.
socket.on('close', ...).
Between each run of the event loop, Node.js checks if it is waiting for any asynchronous I/O or timers and shuts down cleanly if there are not any.
In libuv, the event loop updates its time at the beginning of each loop to achieve timing function, and I/O events are divided into two categories:
- Network I/O uses the non-blocking I/O solution provided by the system, such as epoll on Linux and IOCP on Windows.
- File operations and DNS operations do not have (good) system solutions, so libuv builds its own thread pool to perform blocking I/O.
Understanding process.nextTick()
Process.nextTick is not part of the event loop. Instead, the nextTickQueue is processed after the current operation is completed, regardless of the event loop phase. Here, an operation is defined as a transition from the underlying c/c++ handler, which handles what needs to be executed.
Buffers
The Buffer class is a core library that is released with Node kernel. It allows Node to store raw data to handle binary data. Whenever is necessary to move data in I/O operations node will in most cases use Buffers. The raw data is stored in the Buffer class as an integer array that corresponds to a block of raw memory outside V8 heap.
Conversion between Buffer and JavaScript string objects requires an explicit call to an encoding method to complete. Here are several different string encodings:
- 'ascii' - Only for 7-bit ASCII characters. This encoding method is very fast and discards high-bit data.
- 'utf8' - Multi-byte encoded Unicode characters. Many web pages and other file formats use UTF-8.
- 'ucs2' - Two bytes, Unicode characters encoded in little-endian byte order. It can only encode characters within the BMP (Basic Multilingual Plane, U+0000 - U+FFFF) range.
- 'base64' - Base64 string encoding.
- 'binary' - A way to convert raw binary data to a string, using only the first 8 bits of each character. This encoding method is deprecated and Buffer objects should be used instead.
- 'hex' - Each byte is encoded in binary.
When creating a Buffer, it is important to keep in mind the following rules:
- Buffers are copies of memory, not shared memory.
- Buffers occupy memory as an array, not as a byte array. For example,
new Uint32Array(new Buffer([1,2,3,4]))creates four Uint32Array members with values of[1,2,3,4], not[0x1020304]or[0x4030201].
Slabs
Slab is an non official term for the memory allocation strategy for buffers used by Node.js. If a buffer is smaller than 8k it will be stored in only Slab, otherwise it will be broken in others also containing slabs of 8k.
A slab is a fixed size chunk of memory used to store the data. Storing them in predictable sizes allows node to recycle them once the Buffer is deleted, reducing memory fragmentation and consumption of resources.
Shallow copy
You can mutate values from a buffer directly using [index]. When you slice the buffer it will not create a new Buffer, instead of it, it will return a range of the same slabs that are on that range, so if you modify the main buffer the slice content will be affected.
Deep Copy
If you want to copy a buffer you need to use the .copy method. This procedure is CPU and memory-consuming operation, so don't use it lightly.
Memory Fragmentation
Memory fragmentation describes all unavailable free memory in a system, they can't be used because the allocation algorithm responsible for dynamic memory allocation makes these free memory unusable.
The above slab allocation has obvious memory fragmentation, that is, 8KB of memory is not fully used, and there is a certain waste.
Child Processes
Node runs single threaded, but it can spawn other processes to offload tasks. The module responsible for that is child_prcess which enable us to create processes in the following ways:
execIs the simplest way to create a new process. It creates a process with a given command and a callback that you can use to execute things after the process finishes.
const { exec } = require('child_process');
exec('find . -type f | wc -l', (err, stdout, stderr) => {
if (err) {
console.error(`exec error: ${err}`);
return;
}
console.log(`Number of files ${stdout}`);
});
The stdout and stderr will be a string resulted of the command, so take care to not execute a heavy command otherwise you might have memory problems.
-
execFiledoes the same as exec, but it executes a file without creating a shell. -
spawnalso executes command in a new process, but the result of it is a event emitter which we can use to pipe data in or out from application as buffers.
const { spawn } = require('child_process');
const child = spawn('wc');
process.stdin.pipe(child.stdin)
child.stdout.on('data', (data) => {
console.log(`child stdout:\n${data}`);
});
All the commands above have a sync version of the command.
fork- is a variation of spawn, with the difference that fork has a communication channel with the child process, allowing it to usesendmethod to communicate.
The parent file, parent.js:
const { fork } = require('child_process');
const forked = fork('child.js');
forked.on('message', (msg) => {
console.log('Message from child', msg);
});
forked.send({ hello: 'world' });
The child file, child.js:
process.on('message', (msg) => {
console.log('Message from parent:', msg);
});
let counter = 0;
setInterval(() => {
process.send({ counter: counter++ });
}, 1000);
Node.js Child Processes: Everything you need to know (freecodecamp.org)
TODO: Talk about the cluster api?
Worker Threads
Worker Threads can be a more lightweight option to run things in parallel than Child processes. Child Processes need to spawn a new process that will contain its own V8 and Libuv instances, so in cases that you don't need this level of isolation Worker Threads can be a better solution.
https://developer.mozilla.org/en-US/docs/Web/API/Broadcast_Channel_API
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/SharedArrayBuffer
const {
Worker,
isMainThread,
setEnvironmentData,
getEnvironmentData,
} = require('node:worker_threads');
if (isMainThread) {
setEnvironmentData('Hello', 'World!');
const worker = new Worker(__filename);
} else {
console.log(getEnvironmentData('Hello')); // Prints 'World!'.
}
Not really related to node, but there is a really nice video about concurrency and parallelism in javascript:
Jeff Strauss Multithreaded JavaScript—Web Workers, Shared Memory, and Atomics https://www.youtube.com/watch?v=2w7Ewkpftd4
Native testing
Node.js now has the capability of running tests without the necessity of external libraries. While it can be quite nice to run tests natively, it still doesn't support a good support to more advanced test features like mocking modules.
Here is an example on how you can have tests natively:
const assert = require("node:assert");
const { describe, it, mock } = require("node:test");
describe("calc", () => {
it("sum", () => {
assert.strictEqual(1 + 1, 2);
});
it("subtract", () => {
assert.strictEqual(1 - 1, 0);
});
});
Watching file changes
Node.js fs module has a really nice feature that allows you to listen to changes on a file and trigger an callback. This can be really useful for cli applications that need to run a command when files change.
const { watch } = require("node:fs");
watch("./to_watch.txt", {}, (event) => console.log("It is time to change!"));
Global Object
deep-into-node/chapter12/chapter12-1.md at main · yjhjstz/deep-into-node (github.com)
Debugger
Debugging - Getting Started | Node.js (nodejs.org)
Node CLI
Mastering the Node.js CLI & Command Line Options - RisingStack Engineering